Primitive Scheduler
⚠️ ตัว Go scheduler ไม่ใช่ object เดี่ยว ๆ แยกออกมาต่างหาก แต่มันคือการรวมกันของฟังก์ชันหลาย ๆ ตัวที่ช่วยให้ระบบ scheduling ทำงานได้ อีกอย่างคือมันไม่ได้รันอยู่บน thread เฉพาะของตัวเอง แต่จะรันอยู่บน thread เดียวกับที่ goroutine ทำงานอยู่ด้วย ซึ่งแนวคิดพวกนี้จะเริ่มชัดขึ้นเมื่อคุณอ่านโพสต์นี้ไปเรื่อย ๆ
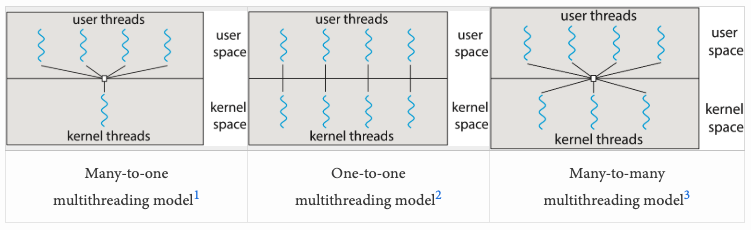
ถ้าคุณเคยทำงานกับ concurrency programming มาก่อน อาจจะคุ้นกับพวก multithreading model มาบ้าง มันคือแนวคิดที่อธิบายว่า user-space thread (เช่น coroutine ใน Kotlin, Lua หรือ goroutine ใน Go) ถูกแม็พลงบน kernel thread (ทั้งแบบเดียวหรือหลายตัว) ยังไง โดยทั่วไปจะมี 3 โมเดล: many-to-one (N:1), one-to-one (1:1), และ many-to-many (M:N)
Go เลือกใช้โมเดลแบบ many-to-many (M:N) ซึ่งเปิดให้มี goroutine หลายตัวแม็พลงบน kernel thread หลายตัวได้ การเลือกแนวทางนี้เพิ่มความซับซ้อนขึ้นก็จริง แต่ช่วยให้ใช้ประโยชน์จากระบบ multicore ได้เต็มที่ และทำให้ Go ทำงานกับ system call ได้มีประสิทธิภาพมากขึ้น โดยแก้ปัญหาทั้งของโมเดล N:1 และ 1:1 ไปพร้อมกัน เพราะ kernel ไม่รู้จักว่า goroutine คืออะไร มันรู้จักแค่ thread ดังนั้นฝั่ง kernel thread จะเป็นคนรัน logic ของ scheduler, รันโค้ดของ goroutine และเรียก system call แทน goroutine
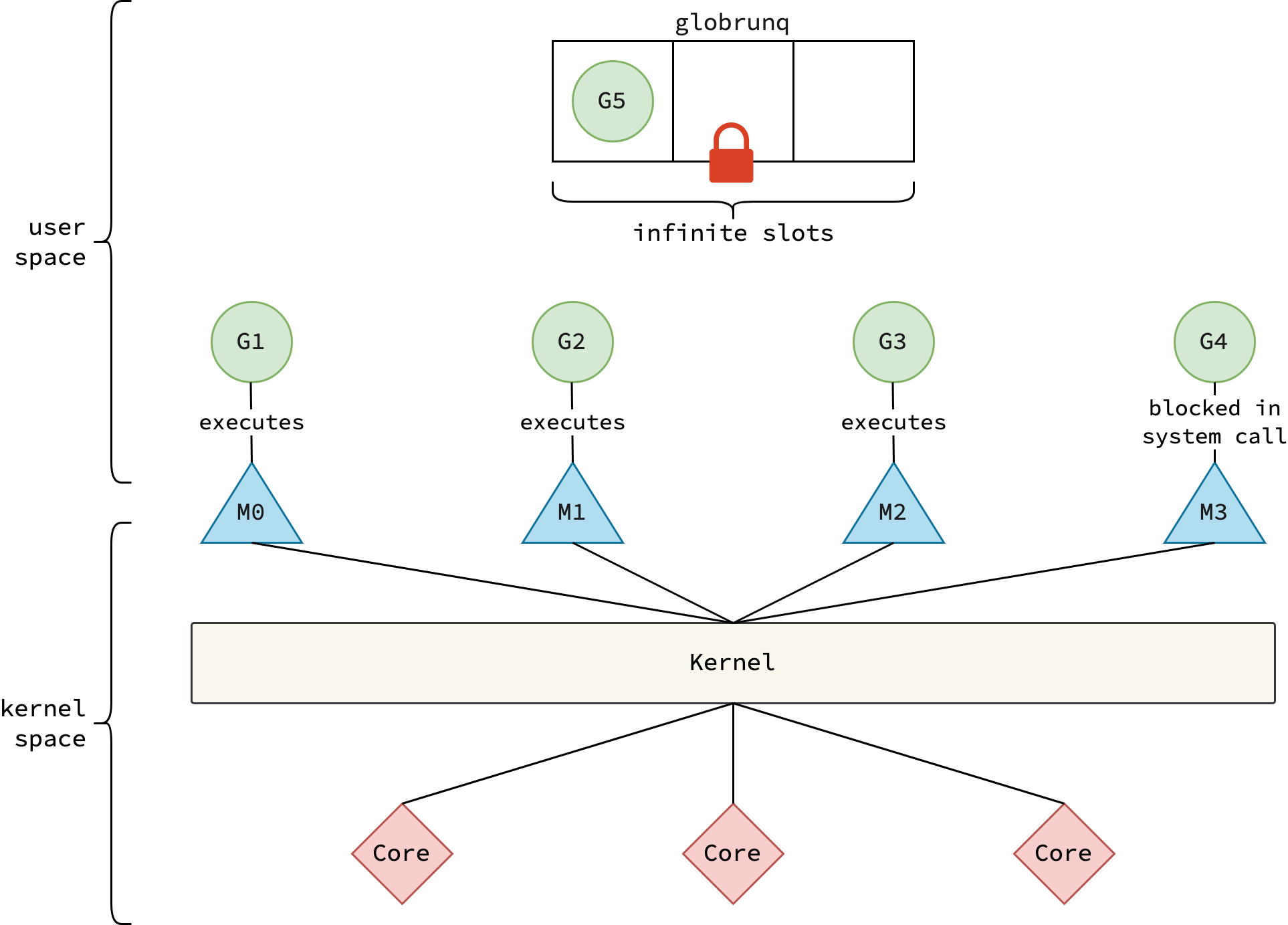
ในยุคแรก ๆ โดยเฉพาะก่อนเวอร์ชัน 1.1, Go ใช้ M:N model แบบง่าย ๆ มาก ๆ โดยมีแค่ 2 entity คือ goroutine (G) กับ kernel thread (M หรือที่เรียกว่า machine) ซึ่งจะมี global run queue อยู่ตัวเดียวไว้เก็บ goroutine ที่พร้อมจะรัน และต้องใช้ lock คุมไว้เพื่อป้องกัน race condition ส่วนตัว scheduler ที่รันอยู่บนแต่ละ thread M ก็มีหน้าที่ดึง goroutine จาก global run queue มา execute
ทุกวันนี้ Go ขึ้นชื่อเรื่อง concurrency model ที่มีประสิทธิภาพมาก แต่ช่วงแรก ๆ มันไม่ได้เป็นแบบนั้นเลย Dmitry Vyukov—หนึ่งใน contributor หลักของ Go—ได้ชี้ให้เห็นปัญหาหลายอย่างใน implementation เดิม ผ่านบทความที่โด่งดังของเขาชื่อ Scalable Go Scheduler Design ว่า “In general, the scheduler may inhibit users from using idiomatic fine-grained concurrency where performance is critical.” เดี๋ยวจะอธิบายให้ละเอียดว่าหมายถึงอะไร
อย่างแรกเลยคือ global run queue มันเป็น bottleneck ด้าน performance เพราะเวลาสร้าง goroutine ใหม่ thread ต้อง acquire lock เพื่อโยน goroutine ลง global run queue และเวลา thread จะหยิบ goroutine ไปทำงานก็ต้อง lock เหมือนกัน ซึ่งคุณน่าจะรู้ว่า lock มันไม่ฟรี มันมี overhead โดยเฉพาะเวลาเกิด lock contention ซึ่งจะทำให้ performance แย่ลงไปอีกในงานที่มี concurrency สูง ๆ
อย่างที่สองคือ thread มักจะต้อง handoff goroutine ที่ตัวเองรับผิดชอบไปให้ thread อื่นต่อ ซึ่งทำให้เกิดปัญหาเรื่อง locality แย่ กับ context switch ที่บ่อยเกินไป ทั้งที่จริง ๆ แล้ว child goroutine มักจะต้องสื่อสารกับ parent goroutine ของมันอยู่แล้ว ดังนั้นถ้า child ได้รันอยู่บน thread เดียวกับ parent มันจะเร็วกว่าและมีประสิทธิภาพมากกว่า
อย่างที่สามคือ Go ใช้ Thread-caching Malloc ดังนั้น thread M ทุกตัวจะมี thread-local cache ที่เรียกว่า mcache ซึ่งเอาไว้ใช้ในการ allocate หรือเก็บ memory ที่ยังไม่ได้ใช้ ถึงแม้ว่า mcache จะถูกใช้แค่กับ M ที่กำลังรัน Go code อยู่ แต่มันก็ถูกแนบติดไปกับ M ที่กำลัง block ใน system call ด้วย (ซึ่งไม่ได้ใช้ mcache เลย) ทีนี้ 1 mcache กินพื้นที่ได้สูงสุด 2MB และมันจะไม่ถูก free จนกว่า thread M จะถูก destroy เพราะงั้นถ้าสัดส่วนของ M ที่รัน Go code เทียบกับ M ทั้งหมดอยู่ที่ประมาณ 1:100 (มี thread ที่ block เยอะมากใน system call) ก็จะทำให้ใช้ resource เกินจำเป็น และทำให้ locality ของข้อมูลแย่ลงแบบชัดเจน